Technologie
Comment une machine apprend-elle réellement ? L'intelligence artificielle repose sur des systèmes techniques qui traitent des données et reconnaissent des modèles. Quiconque comprend ces bases identifie des opportunités pour l'enseignement et gagne en assurance dans l'utilisation de ces nouvelles possibilités.
Perspective technique
Dans ce qui suit, l’accent est mis sur la perspective technologique du triangle de Dagstuhl. Au centre se trouve la compréhension du fonctionnement et des concepts sous-jacents des systèmes d’IA.
Vous découvrirez ici comment les systèmes d’IA sont développés et entraînés techniquement et selon quels principes ils prennent des décisions. De plus, vous aurez un aperçu des concepts centraux sur lesquels reposent les applications modernes comme ChatGPT, Gemini ou les générateurs d’images.
IA faible vs IA forte : Réalité et avenir
De nombreuses personnes ont peur d’un avenir marqué par l’IA, tel qu’il est souvent dépeint dans les films de science-fiction. Dans ces films, nous voyons des robots qui sont d’abord programmés par des humains, mais qui se retournent ensuite contre l’humanité pour devenir des êtres menaçants, pensant et agissant de manière autonome.
Pour surmonter cette peur, il est important de prendre conscience de la différence entre l’IA faible et l’IA forte.

IA faible
L’IA faible, dont font partie les systèmes d’assistance numérique comme Siri ou Alexa ou encore les chatbots, dépend des interventions humaines et se concentre sur l’exécution de tâches spécifiques préprogrammées, basées sur les données d’entraînement mises à disposition (IBM, o.D.). Des tâches clairement définies peuvent ainsi être résolues avec une méthode fixée, ce qui rend l’IA faible bien adaptée à l’automatisation et au contrôle de processus.
IA forte
Pour les systèmes d’IA que nous connaissons des films de science-fiction, nous parlerions en revanche d’une IA forte. Ces systèmes d’IA pourraient par exemple reconnaître eux-mêmes des problèmes, acquérir des connaissances à ce sujet et parvenir à une solution par l’analyse, la solution pouvant être totalement nouvelle. Une IA forte serait donc capable de générer de nouveaux contenus. Un tel développement de l’IA n’est cependant pas en vue aujourd’hui et reste pour l’instant un concept théorique (IBM, o. D.).
L’IA expliquée simplement
Quel est le rapport entre vos goûts musicaux et l’itinéraire de votre système de navigation ? Les deux sont très probablement influencés, au moins en partie, par l’IA ! Derrière de nombreuses applications qui nous accompagnent au quotidien se cache depuis des années une forme d’IA. Que ce soit les applications musicales qui génèrent des suggestions personnalisées ou le système de navigation de la voiture qui nous recommande le chemin le plus court vers notre destination (Akgun & Greenhow, 2022).
Mais qu’est-ce que l’IA et comment fonctionne-t-elle ? Fondamentalement, on entend par intelligence artificielle un logiciel qui exécute certaines tâches qui nécessiteraient en règle générale l’intelligence humaine.
RTS OKI Explication vidéo : Intelligence artificielle : mais comment ça fonctionne ?
Prompting : Interaction entre humain et machine
Selon le groupe de travail IA du canton de Berne, le mot « prompter » vient de l’anglais et signifie quelque chose comme « inciter » ou « solliciter ». Plus précisément, il s’agit d’une instruction ciblée donnée à une IA pour qu’elle exécute une tâche spécifique. Un prompt est fondamentalement saisi dans le champ de saisie d’un outil spécifique (par exemple Gemini, ChatGPT, Mistral, etc.).
Le bouton suivant vous ouvre un document du canton de Berne avec des conseils sur le prompting dans l’utilisation de l’IA générative.
Le Prompt Engineering décrit l’art de donner à l’IA des instructions claires et bien formulées afin qu’elle fournisse des réponses adaptées et de haute qualité. Les modèles d’IA générative comme ChatGPT, DALL·E ou Gemini réagissent fortement à la formulation de la saisie. En bref, de bons prompts mènent à de meilleurs résultats.
Un prompt soigneusement conçu aide l’IA à mieux comprendre l’intention derrière une demande et à générer des réponses plus précises, plus pertinentes et plus créatives. Cela permet d’économiser du temps lors du post-traitement et les résultats sont plus proches de la solution souhaitée.
Les systèmes d’IA générative travaillent avec de grands modèles de langage (en anglais Large Language Models ou LLM), qui comprennent la langue et reconnaissent des modèles dans des quantités gigantesques de données. Pour ce faire, les Prompt Engineers utilisent différentes techniques :
– Zero-Shot-Prompting: L’IA reçoit une nouvelle tâche sans exemples.
– Few-Shot-Prompting: L’IA reçoit quelques exemples de réponses pour s’orienter.
– Chain-of-Thought-Prompting: Une tâche complexe est décomposée en étapes intermédiaires pour que l’IA pense de manière plus logique.
Systèmes d’IA hallucinants
Les hallucinations dans l’IA surviennent lorsqu’un modèle génère des réponses qui ne peuvent pas être déduites de ses données d’entraînement ou qui en sont incorrectement reconstruites. Techniquement, cela se produit parce que les grands modèles de langage (en anglais Large Language Models) prédisent des modèles, et non des vérités. Lorsque des lacunes dans les données, des données d’entraînement biaisées, un surapprentissage (overfitting) ou des estimations de probabilités erronées surviennent, le modèle génère des informations qui semblent plausibles, mais qui sont fausses. De plus, la haute complexité des Transformeurs peut amener le modèle à « inventer » des liens pour fournir une réponse statistiquement adaptée (IBM o.J.). Certains systèmes d’IA peuvent aussi être induits en erreur intentionnellement si quelqu’un modifie très légèrement les entrées. Ces manipulations minimes de l’entrée (attaques adverses, en anglais adversarial attacks) peuvent déclencher de telles hallucinations (Xu et al., 2020).
Apprenez-en plus sur la gestion des systèmes d’IA sujets aux hallucinations dans Socitété & Culture.

Approfondissement de la perspective technique
Si vous souhaitez vous pencher plus en détail sur l’intelligence artificielle, vous trouverez dans la section suivante plus d’informations sur les sujets :
Dans l’apprentissage automatique (ML), les ordinateurs tentent d’apprendre à partir d’expériences, de manière similaire aux humains. Au lieu que tout soit programmé étape par étape, la machine reconnaît elle-même des modèles dans les données et s’améliore ainsi constamment. Un système ML se compose de trois parties :
- Processus de décision : L’ordinateur reçoit des données et tente d’en prédire quelque chose (p. ex. reconnaître un modèle ou trier quelque chose).
- Fonction d’erreur : Ensuite, le système vérifie la qualité de cette prédiction. Il la compare avec des exemples connus et voit où il s’est trompé.
- Optimisation : L’ordinateur adapte ses « poids » (c’est-à-dire les réglages internes du modèle) et réessaie. Ce cycle se répète de nombreuses fois jusqu’à ce que les prédictions soient aussi précises que possible.
Ainsi, la machine apprend étape par étape à partir de données et devient plus fiable avec le temps.
Comment une IA apprend-elle ?
Lors de l’entraînement du modèle, une IA apprend à partir de nombreux exemples comment résoudre des tâches. En d’autres termes, l’IA est donc « enseignée ». L’objectif consiste à apprendre à partir de données d’exemple pour pouvoir ensuite résoudre des tâches de manière autonome. Cela inclut par exemple la reconnaissance d’images, la compréhension de textes ou la réalisation de prédictions. Tout au long du processus, le modèle apprend à optimiser ses performances sur des données d’entraînement qui sont aussi proches que possible des cas d’application réels. Mieux ces données reflètent la réalité, plus le modèle pourra évaluer avec précision de nouvelles situations plus tard. Durant l’entraînement, les paramètres du modèle sont ajustés de manière à ce que l’écart entre la réponse correcte et la réponse prédite devienne de plus en plus petit.
La « fonction de perte » (loss function) doit être minimisée pour maintenir l’erreur aussi faible que possible. Dans l’apprentissage par renforcement (voir ci-dessous), c’est en revanche une « fonction de récompense » (reward function) qui est maximisée.
Le processus d’entraînement se déroule par cycles jusqu’à ce que le modèle fonctionne de manière fiable :
- Collecter et préparer les données
- Entraîner le modèle avec les données
- Vérifier les résultats (mesurer l’erreur)
- Ajuster les paramètres et répéter
Parfois, un modèle est encore affiné après l’entraînement de base (en anglais fine-tuning) pour l’adapter à de nouvelles tâches.
Trois types d’apprentissage
Apprentissage supervisé
L’IA reçoit des exemples avec les réponses correctes et apprend à les imiter.

Apprentissage non supervisé
L’IA ne reçoit que des données et y cherche elle-même des structures ou des groupes.

Apprentissage par renforcement
L’IA essaie des actions et apprend grâce aux retours (feedbacks). Similaire au principe d’essai et de récompense.

(Bergmann & Stryker für IBM)
(Illustrationen de Seegerer, Michaeli & Jatzlau)
Réseaux de neurones – Structure et fonctionnement comme base de l’intelligence artificielle
Un réseau de neurones est un concept central de l’intelligence artificielle et s’inspire, sous une forme simplifiée, du fonctionnement du cerveau humain. Il se compose de nombreux neurones artificiels interconnectés qui traitent les informations étape par étape. Chaque neurone reçoit des valeurs d’entrée, les pondère plus ou moins fortement et calcule un résultat qui est transmis à d’autres neurones. L’apprentissage s’effectue en entraînant le réseau avec de nombreux exemples. Il compare ses sorties avec les solutions correctes et ajuste progressivement les pondérations des connexions. Ce processus est répété jusqu’à ce que le réseau fournisse des résultats aussi précis que possible. Plus un réseau de neurones possède de couches, plus il peut saisir des structures complexes. Dans ce cas, on parle de Deep Learning (apprentissage profond).
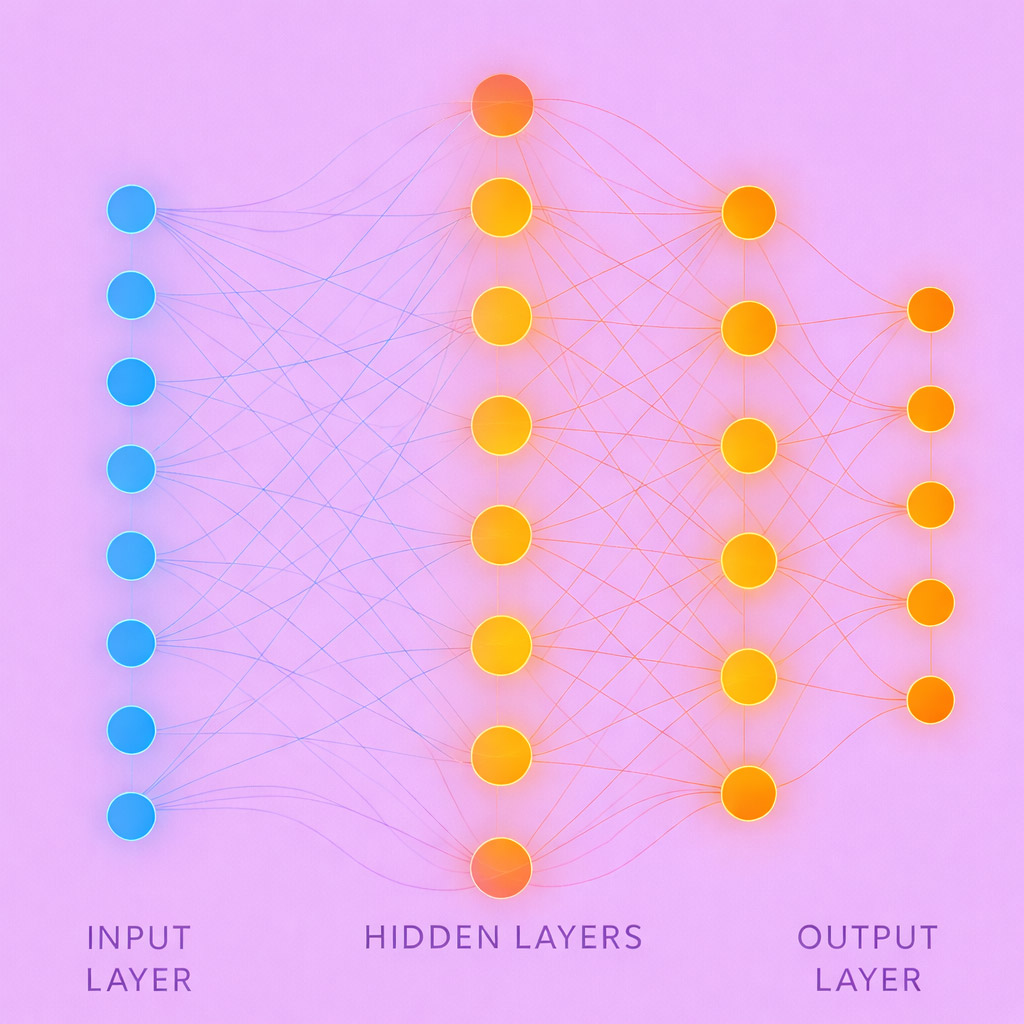
Un réseau de neurones est structuré en couches (Layers) :
La structure d’un réseau de neurones est organisée par couches. La couche d’entrée (Input Layer) reçoit les données brutes, par exemple des valeurs numériques, des pixels d’image ou des mots isolés. La couche de sortie (Output Layer) fournit le résultat final, comme une classification, une prédiction ou une décision. Entre les deux se trouvent une ou plusieurs couches cachées (Hidden Layers), dans lesquelles le réseau reconnaît des modèles complexes, des liens et des significations.
Le Deep Learning est une forme particulière de l’apprentissage avec des réseaux de neurones. Le terme « deep » (profond) fait référence au fait que ces réseaux sont constitués de très nombreuses couches successive.
Grâce à cette profondeur, les modèles de Deep Learning peuvent reconnaître des modèles particulièrement complexes, par exemple dans des images, la langue ou des textes. Ils sont la base de nombreuses applications d’IA modernes comme les assistants vocaux, les générateurs d’images ou les services de traduction. Le Deep Learning nécessite de grandes quantités de données et une puissance de calcul élevée, mais il est en contrepartie très performant et fournit de très bons résultats.